ByteBuf
数据容器
- 可以进行扩展
- 容量按需增长
- 读写切换不需要调用flip
- 读写使用不同索引
- 方法链式调用
- 引用计数
- 池化

零拷贝
Netty 零拷贝完全是基于(Java 层面)用户态的,它的更多的是偏向于数据操作优化这样的概念
- 通过 wrap 操作把字节数组、ByteBuf、ByteBuffer 包装成一个 ByteBuf 对象, 进而避免了拷贝操作
- 支持 slice 操作, 因此可以将 ByteBuf 分解为多个共享同一个存储区域的 ByteBuf,避免了内存的拷贝
- CompositeByteBuf 类,它可以将多个 ByteBuf 合并为一个逻辑上的 ByteBuf,避免了各个 ByteBuf 之间的拷贝
使用模式
- 堆缓冲区
ByteBuf将数据存储在JVM的堆空间中
ByteBuf heapBuf = ...;
if (heapBuf.hasArray()) { ← -- 检查ByteBuf 是否有一个支撑数组
byte[] array = heapBuf.array(); ← -- 如果有,则获取对该数组的引用
int offset = heapBuf.arrayOffset() + heapBuf.readerIndex(); ← -- 计算第一个字节的偏移量。
int length = heapBuf.readableBytes(); ← -- 获得可读字节数
handleArray(array, offset, length); ← -- 使用数组、偏移量和长度作为参数调用你的方法
}
- 直接缓冲区
这种模式下的ByteBuf支持通过本地调用分配内存
所以直接缓冲区的数据在堆外,不会被GC处理
ByteBuf directBuf = ...;
if (!directBuf.hasArray()) { ← -- 检查ByteBuf 是否由数组支撑。如果不是,则这是一个直接缓冲区
int length = directBuf.readableBytes(); ← -- 获取可读字节数
byte[] array = new byte[length]; ← -- 分配一个新的数组来保存具有该长度的字节数据
directBuf.getBytes(directBuf.readerIndex(), array); ← -- 将字节复制到该数组
handleArray(array, 0, length); ← -- 使用数组、偏移量和长度作为参数调用你的方法
}
- 复合缓冲区
这种模式下允许多个ByteBuf聚合起来,提供一个ByteBuf整体视图来进行操作
字节级操作
- 随机访问
ByteBuf buffer = ...;
for (int i = 0; i < buffer.capacity(); i++) {
byte b = buffer.getByte(i);
System.out.println((char)b);
}
不会改变索引的值
- 顺序访问
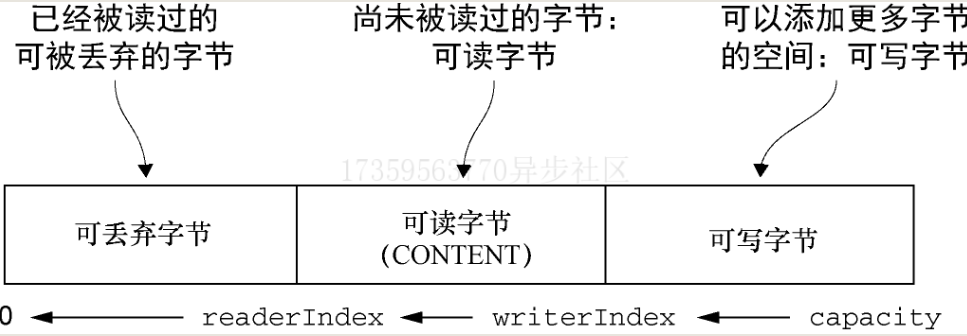
调用discardReadBytes()可以回收可丢弃字节的空间
读取所有数据
ByteBuf buffer = ...;
while (buffer.isReadable()) {
System.out.println(buffer.readByte());
}
写入数据
ByteBuf buffer = ...;
while (buffer.writableBytes() >= 4) {
buffer.writeInt(random.nextInt());
}
索引管理
- readerIndex(int):设置读索引位置
- writerIndex(int): 设置写索引位置
- clear():将读索引写索引重置为0
查找
// 查找回车符(\r)
ByteBuf buffer = ...;
int index = buffer.forEachByte(ByteBufProcessor.FIND_CR);
派生缓冲区
- duplicate()
- slice()
- slice(int, int)
- Unpooled.unmodifiableBuffer(…)
- order(ByteOrder)
- readSlice(int)
- copy()
这些方法都会返回一个新的ByteBuf实例
- 读/写
- get和set操作,从给定的索引开始,并且保持索引不变;
- read和write操作,从给定的索引开始,并且会根据已经访问过的字节数对索引进行调整。
- 其他操作
| 名称 | 描述 |
|---|---|
isReadable() |
如果至少有一个字节可供读取,则返回true |
isWritable() |
如果至少有一个字节可被写入,则返回true |
readableBytes() |
返回可被读取的字节数 |
writableBytes() |
返回可被写入的字节数 |
capacity() |
返回ByteBuf可容纳的字节数。在此之后,它会尝试再次扩展直 到达到maxCapacity() |
maxCapacity() |
返回ByteBuf可以容纳的最大字节数 |
hasArray() |
如果ByteBuf由一个字节数组支撑,则返回true |
array() |
如果 ByteBuf由一个字节数组支撑则返回该数组;否则,它将抛出一个UnsupportedOperationException异常 |
ByteBufHolder
- 支持缓冲区池化
- 从池中复用ByteBuf
| 名称 | 描述 |
|---|---|
content() |
返回由这个ByteBufHolder所持有的ByteBuf |
copy() |
返回这个ByteBufHolder的一个深拷贝,包括一个其所包含的ByteBuf的非共享副本 |
duplicate() |
返回这个ByteBufHolder的一个浅拷贝,包括一个其所包含的ByteBuf的共享副本 |
ByteBuf分配
ByteBufAllocator
- 池化
- buffer 返回基于对或者直接缓存存储
- headBuffer 返回基于堆内存
- directBuffer 返回基于直接内存
- compositeBuffer
- ioBuffer 返回套接字的IO操作buffer
实现:
- PooledByteBufAllocator
- 池化
- UnpooledByteBufAllocator
- 每次调用都会返回一个新实例
Unpooled缓冲区
提供了一些静态方法来创建ByteBuf实例
ByteBufUtils
- hexdump 以16进制打印缓冲区
- equals 比较两个ByteBuf
引用计数
ByteBuf 与 ByteBufHolder 都实现了引用计数
boolean released = buffer.release(); ← -- 减少到该对象的活动引用。当减少到0 时,该对象被释放,并且该方法返回true
访问一个引用计数被释放的对象 会抛出异常